What we can learn from public data breaches to better protect our cloud investments
Alan Williamson
Aug 6, 2019

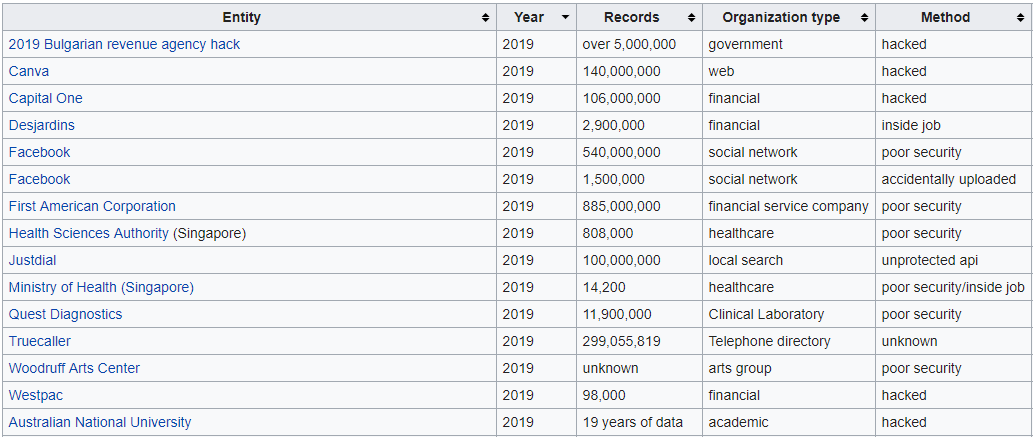
It is only the 8th month of 2019 and we are already racking up quite the list of data breaches, by a variety of means including direct hacking, poor security, disgruntled employees and social engineering. The first week of August alone, has witnessed not just one massive data breach but two hitting the headlines — Capital One (106M users) and StockX (6.8M users).
StockX,
an online sneaker marketplace, suffered their breach back in May, but only decided to go public
this week, some 3 months after the fact, when it was discovered their data was being shopped on the dark
web. The StockX breach didn’t contain any payment or credit details, that said, the usual suspects of
name, address, email, hashed-passwords were all made available, with some customers noting unusual
activity on their credit cards.
Capital One, a
little more responsive, went public relatively quickly after their breach, which had
resulted in a much richer haul of data including social security and bank account details of those who
had applied for a credit card in the last 14 years. This is garnering a lot of media attention, not only
because of the magnitude of the leak of a trusted public bank, but it also points towards security
concerns with the usage of the public cloud, more specifically Amazon’s AWS cloud service.
The natural inclination is to ask if Capital One (with all their resources, expertise, and deep
financial pockets) can’t secure their AWS cloud, then how on earth are you going to manage your own much
smaller cloud account on a fraction of their budget?
Given the circumstances, it is a plausible question to ask. Let us review the breach, the logistics, the
aftermath, and how you can learn from their missteps.
Capital One — Logistics
The breach was the result of a 3rd party consultant, contracted by Capital One, taking advantage of a
poor security configuration from one of the servers hosted within Amazon to get temporary access keys
that were subsequently used to access data sitting in S3 buckets (we believe).
The fact that the consultant was an ex-Amazon employee, some 3 years prior, has nothing to do with the
hack itself — that just makes the story a little more “Hollywood”. There was no insider AWS information
that made the breach possible. The information needed for the hack was a result of general AWS know-how
and a little internal Capital One knowledge.
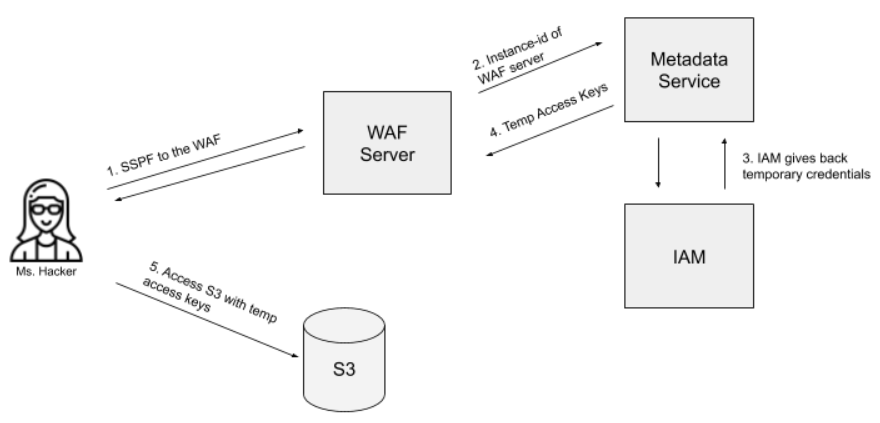
It is worth noting, that what follows is speculation on how the attack went down, piecing together the
pieces of information that have been made available over a wide range of sources.
It is thought the consultant tricked the WAF (Web Application Firewall) server into giving them the
necessary access keys that allowed them unfettered access to the data sitting in S3 buckets (see diagram
above). This was performed using a Server Side Request Forgery (SSRF) request that allowed them to make
a call to the AWS metadata service (which is used by EC2 instances to basically self-config) to retrieve
a temporary IAM role, with the same level of rights, that the EC2 instance was running under.
Using these credentials, the consultant could then make successful and secure requests to S3, retrieving
whatever data they desired.
Security fell down on a number of fronts here:
-
The WAF server, which was thought to be an Apache web server, running the WAF module, was not configured properly and allowed the spoof request to be made.
-
The WAF server was created with an elevated IAM privilege that gave it far more access than it needed, including broad access to a large number of S3 buckets.
-
Insufficient logging and auditing of the usage of IAM accounts.
The irony that it was the WAF, the very server that is designed to prevent attacks, was the one that
proved to be at fault, should not be overlooked. Once the server gave back the temporary IAM
credentials, the consultant was able to use those IAM to access other AWS resources, including S3
buckets with little effort. Files were obtained and subsequently posted on GitHub. Another piece of the
story that is interesting, is that Capital One did not discover this problem themselves — they had to be
informed by email tip-off that this data had been available on GitHub for a number of days.
Speaking of irony, Capital One had just hired Netflix’s senior security expert Will Bengtson as their
head of cloud security two months prior — what a start to his tenure — and Bengtson had actually
authored an article on this very type of vulnerability when he was back at
Netflix to-the-year previous.
That said we imagine Bengtson will have no problems getting budget approved for security going forward.
The consultant was also discovered with files from other large public companies, where it is thought
they performed the same technique on others.
Who was at fault
Capital One invests heavily in the cloud, marketing themselves as a development company, instead of a
bank. They have a huge amount of staff (in and around 9,000 developers) and a large number of
external
consultants. They pride themselves on being a large Agile development shop, with a DevOps culture, all
producing their own micro-services within AWS. With that many people, actively deploying their own code
to the cloud, it was inevitable that something could be missed along the way.
The important aspect to note, this is not the fault of Amazon. Amazon takes security very seriously and
offers a wide range of tools to make sure their services are as secure as possible. AWS offers a full
suite of services that include a robust set of security features; features that are only as effective as
those responsible for its implementation and maintenance. In Capital One’s case, while it is unclear
which of those services were being used, it was their own managed server that was the problem, not an
AWS service.
As systems get larger, the opportunity for things to be overlooked magnify increasingly. The vast
majority of cloud installations are nowhere near the size of what Capital One maintains, and as such,
there is usually a smaller team overseeing a much smaller cloud footprint. This makes it less likely
that things will slip by (though not impossible).
That notwithstanding, there are things that Amazon could do better to make things harder for these types
of attacks to exist.
-
Limit the scope of the temporary credentials retrieved from the Metadata service layer.
-
Allow S3 buckets to be accessible only from inside a VPC as you can with other AWS services.
5 things you can do
Capital One is yet another canary-in-the-coal-mine for anyone running on a public cloud. It is a
reminder to review security procedures, the systems that are put in place, the code that is running, and
the amount of data being held.
Here are 5 things you can review as you look at your own cloud architecture with respect to security:
-
Credentials
Review all access credentials. Of the ones that are still active, do they have the principle-of-least-privilege applied to them? For those that are not active, can you remove them completely? For those active, can you recycle their keys/passwords? -
Open Ports
Do you know all the ports that are listening on the public network? Of those ports, what service is managing that request and have they been updated with the latest security patches. -
Logging
How much logging do you have? Do you know when a request was refused or malformed? Do you know which services are accessing services/data? Can you spot unusual activity; large file downloads from archives? -
Services
Are you using the security services from your cloud provider to protect your servers? Are you regularly running security scans to ensure all services are doing what you think they are doing? -
Data Quality
How much data are you keeping and where are you keeping it? Do you really need that much data? Can you desensitize it? Can it be archived off, far away from the front-end services?
In conclusion
Capital One’s breach has little to do with the public cloud, but more to do with security as a whole.
There was a number of gates that were left open, that would have had similar outcomes had it been a
private data center. The hack was clever but yet simple at the same time — why bother trying to hack the
lock when you can steal the key and walk on in.
As part of our due diligence
work, we see all sorts
of security problems crop up, with most stemming
from the attitude “we didn’t think of that”. Sometimes you need that extra pair of eyes to ask
the
questions you didn’t think of asking and to confirm the security you do have, is indeed doing what you
think it is doing.
What we do see a lot of, is a lack of adequate (in most cases none) logging and auditing of access.
Irrespective of your security, you should always have a handle on who is accessing your data, both
internally and externally.

The primary takeaway here is that you can’t outsource security. It is something every company has to take
responsibility for, irrespective of whether it is in the public cloud or their own private data center.
You cannot blame the door for being open if no one turned the key to lock it, or worse still, locked the
door and put the key under the mat.
With respect to your own cloud account (be it Amazon, Azure or any of the others) it is vital you take
no security shortcuts, frequently review security protocols, and assume the principle-of-least-privilege
when securing resources and continually run checks against your services, using the tools made available
by the cloud provider and other 3rd parties.
It is an ongoing exercise, not something you do once a quarter/year. It has to be baked into every part
of your engineering and IT infrastructure process.
Above all else, never assume it could not happen to you. Complacency is the root of all security
breaches.
- Capital One
- AWS
- Data Security
- Demystifying


